

NovaSky @NovaSkyAI
Building SkyRL at @BerkeleySky Join the Slack community: https://t.co/mSO97T61vR github.com/NovaSky-AI/Sky… Berkeley, California Joined January 2025-
Tweets148
-
Followers3K
-
Following18
-
Likes228

🏹5 Days of Trajectory. Day 3 - An Open Source Training Stack for Continual Learning Building the platform for continual learning requires both partnering with pioneering AI companies, as we showed on Day 2 with Harvey, and working toward frontier research, which we are highlighting today. Continual learning means models that improve hourly from real production use. But with the size of frontier models, this becomes quite difficult. A Qwen-397b would need to spin up and tear down repeatedly across six GPU nodes, and that's valuable time gone. Our contribution is Continual LoRA (C-LoRA): many lightweight adapters running at once on one shared base model. Our insight centers on where the parallelism lives: instead of splitting one giant job across nodes, we load-balance many small jobs over a single base. The result: 2.81x experiment throughput over single-tenant training, with no regression on rewards. We built this together, with @anyscalecompute, @NovaSkyAI, and generous support from @GoogleCloud and @GoogleStartups. We've open-sourced on SkyRL as one of the first multi-LoRA, RL training platforms, so that every team can get to continual learning faster. We’re very excited to see what you build, please reach out!


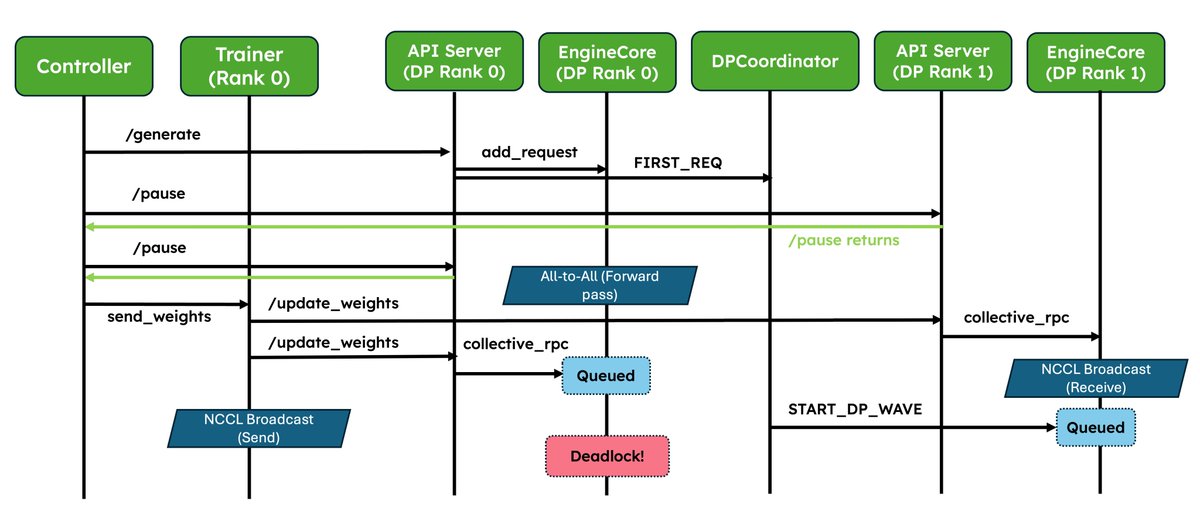
We've shipped two major upgrades for RL✨! 1. Native weight syncing APIs: Standardizes weight transfer, provides optimized implementations for NCCL and CUDA IPC out of the box, and also lets frameworks easily bring their own. 2. Improved pause/resume for Async RL: Careful coordination between DP ranks so that engines don’t deadlock. Validated at scale in P/D, wide-EP setups! In collaboration with @anyscalecompute, @NovaSkyAI, and @RedHat. More and more RL frameworks are using vLLM as the default for inference, details in the blog 👇 vllm.ai/blog/2026-05-2…
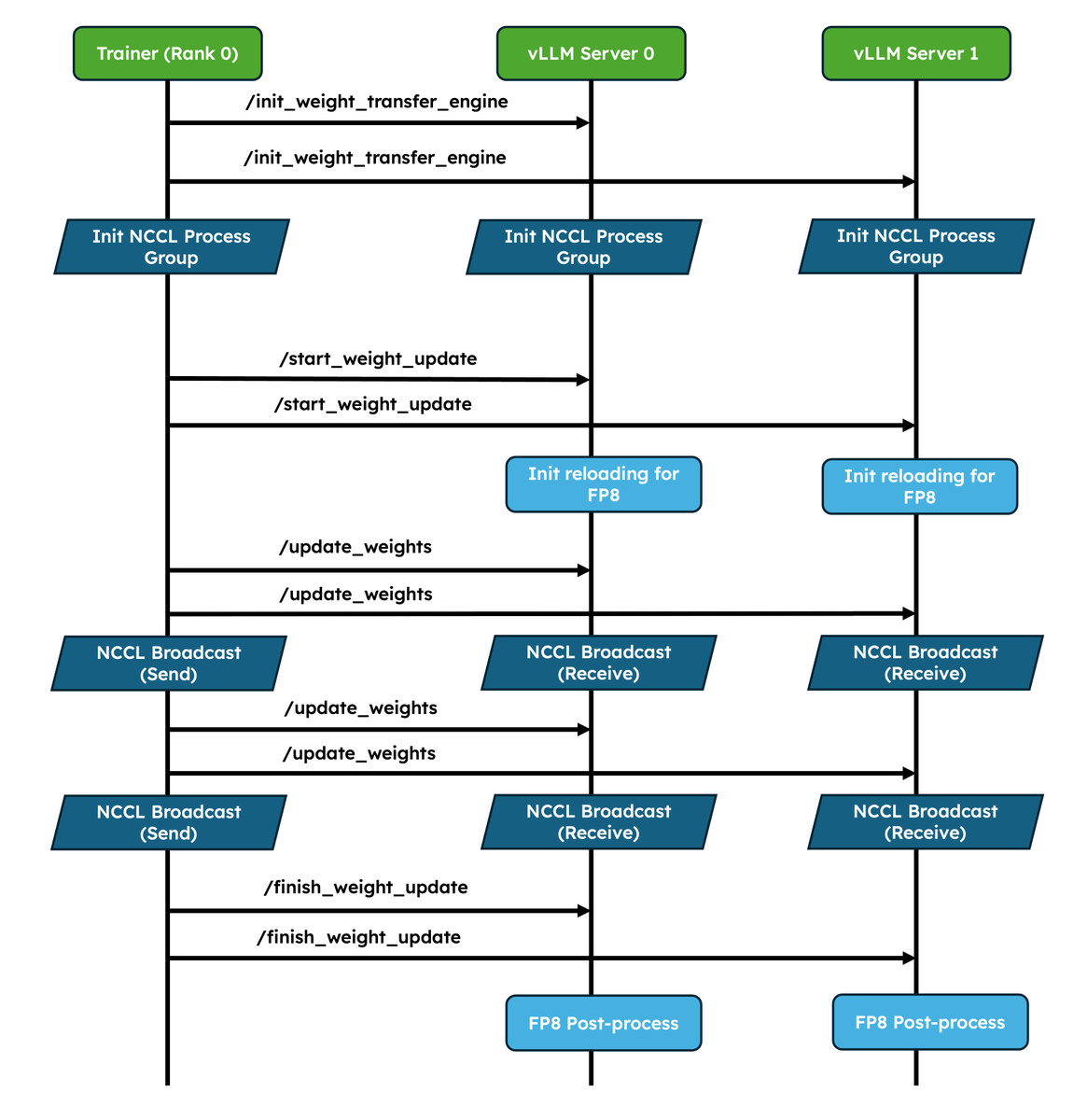
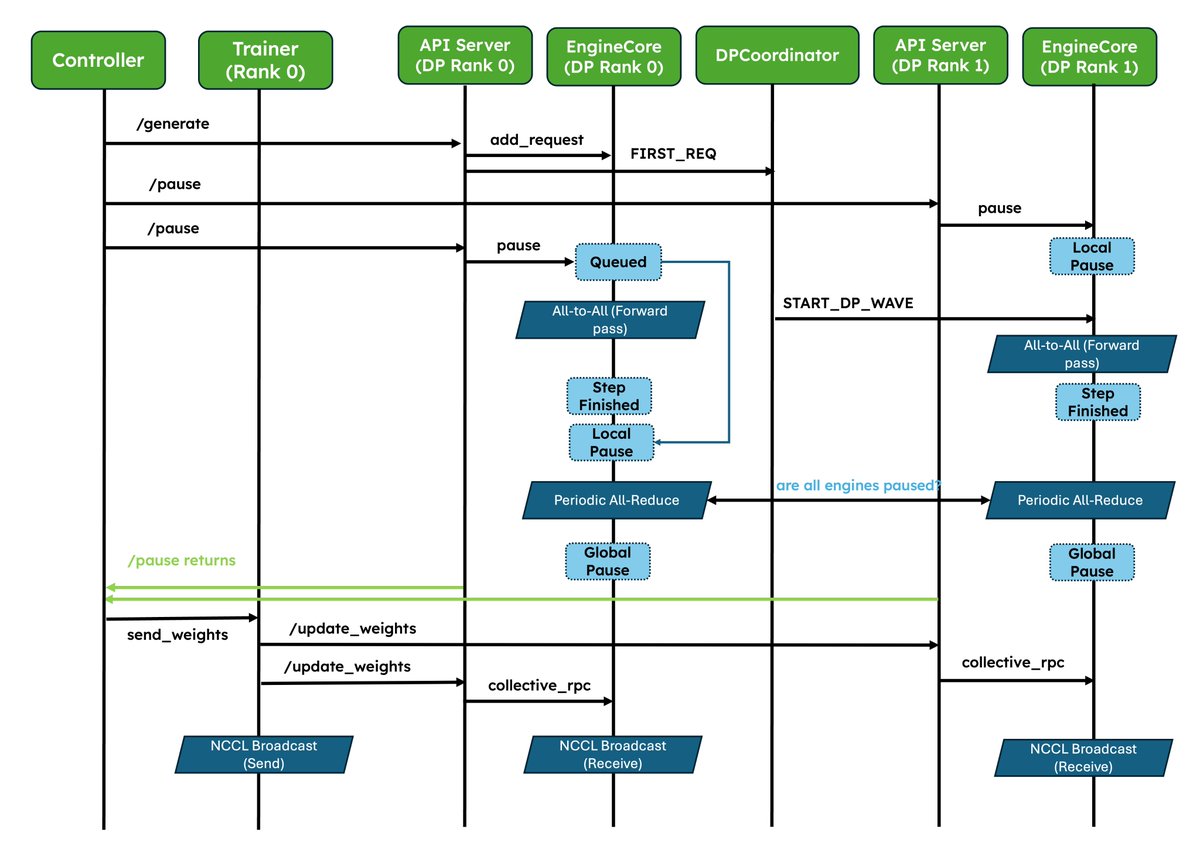
Amazing work! More and more RL frameworks are using vLLM as default. @vllm_project along with @anyscalecompute and @NovaSkyAI revamped weight syncing and improved wide-ep deployment for rollout!
Excited to share some of our work on improving vLLM for RL! A number of RL frameworks, including SkyRL, use vLLM for inference, and we’ve noticed some common problems: 1. Weight syncing between training and inference is implemented in an ad-hoc fashion and duplicated across
it's been a really great experience working w/ @j316chuck and the @trajectorylabs team on building out their post-training stack for continual learning on top of SkyRL really excited to continue collaborating and seeing how the team can push the frontier for continual learning!

Today, @MichaelElabd, @QuantumArjun, and I are excited to announce Trajectory. We are a research lab and product company building the platform for Continual Learning. Our platform unlocks the signal already sitting in product usage, so companies can continuously post-train
Awesome to see Trajectory labs launch out of stealth! It's been great collaborating with them in building out multi-LoRA for SkyRL!

So excited to share that I’ve joined @trajectorylabs! We’re pushing the frontier of RL research to build the platform for continual learning - systems that learn and evolve alongside your products in real time. We believe in a world where everyone has the power to own their own
Today, @MichaelElabd, @QuantumArjun, and I are excited to announce Trajectory. We are a research lab and product company building the platform for Continual Learning. Our platform unlocks the signal already sitting in product usage, so companies can continuously post-train large-scale agentic models that outperform the frontier. @trajectorylabs We’ve raised $15M from @Conviction, @BessemerVP, @radicalvcfund, @jeffdean, @drfeifei and more. We’re partnering with some of the best AI-native companies: @ClayRunHQ @Harvey, @DecagonAI, @mercor_ai, @RogoAI to power their agentic systems, some of which we are already in production with. We’ve brought together a world class research team from DeepMind, OpenAI, Apple, Meta Superintelligence, Amazon AGI, Scale AI, and an elite product team from Stripe and Figma. AI will never again start on day one. Every correction, every retry, every edit will make products smarter. This is Continual Learning.
Super cool work built with SkyRL! Have also thought about how it's so wasteful not to train on the observation tokens. Can't wait to upstream it:)

A 4B RLM trained with SkyRL that matches Sonnet 4.6, very cool work!

Reinforcing Recursive Language Models Can a 4B model learn to recursively call itself to answer hard long-context questions? We RL fine-tuned a small model to behave as a native RLM. On evidence selection across scientific papers, our 4B RLM matches Sonnet 4.6 in quality

Check out VLM training in SkyRL! SFT / multi-turn RL, LoRA / full-finetuning, tinker-compatible as well!

SkyRL now supports end-to-end vision-language post-training, from SFT to agentic RL, and adds vision model support to SkyRL’s Tinker interface! Existing multimodal cookbooks, e.g. VLM classification, work out of the box:


🚀 Excited to share the training & inference results for UCCL-EP: a portable, high-performance expert-parallel communication library across heterogeneous GPU + NIC hardware. 💻 Code: github.com/uccl-project/u… 📝 Blog: uccl-project.github.io/posts/uccl-ep-… 📈 Highlights: • Up to 45% faster Megatron-LM training vs RCCL on 128 AMD GPUs • Up to 40% faster SGLang inference vs NCCL on 32 H200 GPUs • Up to 25% lower vLLM TPOT vs NCCL • Up to 2.3x better EP dispatch/combine on AWS EFA 🔁 Fully portable across heterogeneous GPU/NIC hardware and a drop-in replacement for DeepEP Amazing team: Chon Lam Lao, @yangzhouy, Yihan Zhang, Chihan Cui, Zhongjie Chen, Zhiying Xu, @KaichaoYou, Zhen Huang, Zhenyu Gu, Costin Raiciu, Scott Shenker, @istoica05

Great work from the @OpenHandsDev community and CMU! Open source SOTA on code localization via RL. Happy to see the beautiful reward curves trained with SkyRL!

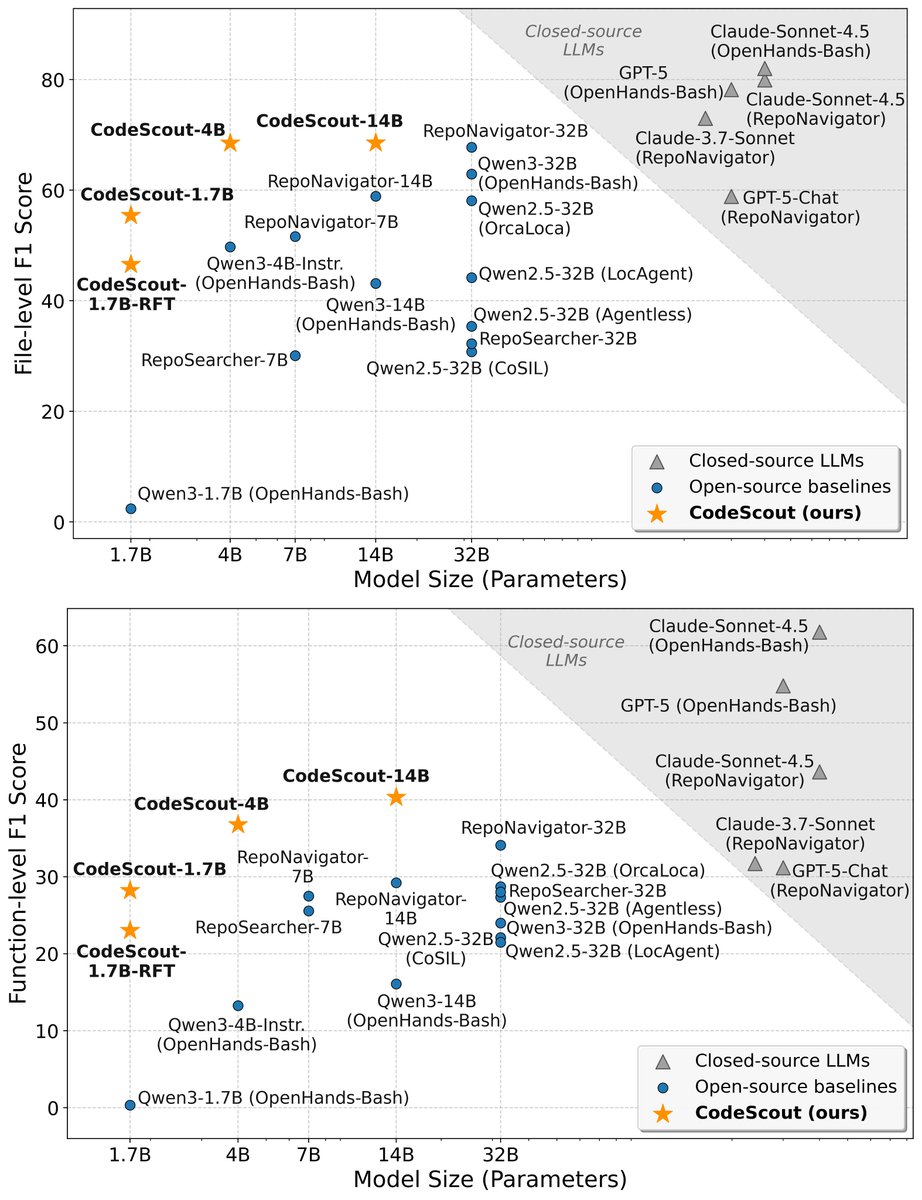
Can we train code agents to search relevant locations in a codebase only using a terminal? Introducing CodeScout: an effective RL recipe for code search 🚀 🏆 Outperforms 18x larger OSS LLMs 🔥 Comparable to proprietary LLMs 📈 SoTA on SWE-Bench Verified, Pro, & Lite 🧵 [1/N]
Excited to see SkyRL sharing their work on inference and vLLM in RL at the LLMs on Ray office hours this Thursday. If you’re exploring using vLLM in RL workflows, this will be a great session to join. See you there 👇

Hi all, extending the invite to the LLMs on Ray office hours next Thursday, 3/5 9:30-10:30AM PT! We will be hosting @erictang000 and @sumanthrh from the @NovaSkyAI SkyRL project to present on inference/vLLM in RL and take questions from the group. After, there will be time for
We’ve been consistently surprised lately by how capable frontier models are at handling complex kernel implementation and system optimization. Check out this work as a step toward automating AI infrastructure building!
Introducing our new work K-Search: LLM Kernel Generation via Co-Evolving Intrinsic World Model — a new paradigm for automated GPU kernel generation, achieving SoTA results. 🔍 Big insight: Traditional methods treat LLMs as stochastic code generators inside heuristic loops — but


Introducing our new work K-Search: LLM Kernel Generation via Co-Evolving Intrinsic World Model — a new paradigm for automated GPU kernel generation, achieving SoTA results. 🔍 Big insight: Traditional methods treat LLMs as stochastic code generators inside heuristic loops — but this misses a key point: LLMs are powerful planners with rich domain priors. 🧠 Core idea: K-Search uses the LLM itself as a co-evolving world model — one that plans + updates beliefs + guides search decisions based on experience. 📌 This decouples high-level strategy (intent) from low-level code implementation, allowing the optimizer to pursue multi-step transformations even when intermediate implementations don’t immediately improve performance. 📈 Key results: 🔥 Our discovered kernels are ~2.10× average speedup vs state-of-the-art evolutionary search across 4 FlashInfer kernels on H100/B200. 🔥 Up to 14.3× gain on complex Mixture-of-Experts (MoE) kernels. 🔥 State-of-the-art performance on GPUMode TriMul (H100) task — beating both automated and human solutions. 🙏 Acknowledgements This work is developed in @BerkeleySky, w/ the amazing @ziming_mao, @profjoeyg, and @istoica05. We thank @DachengLi177, @MayankMish98, @randwalk0, @pgasawa, @fangz_zzu, and @tian_xia_ for helpful discussion and feedback. We also thank the generous compute support from @databricks, @awscloud, @anyscalecompute, @nvidia, @Google, @LambdaAPI, and @MayfieldFund. 👨💻 GitHub: github.com/caoshiyi/K-Sea… 📄 arXiv: arxiv.org/pdf/2602.19128…
Excited to see SkyRL being used by systems research to study how agentic RL workload can be optimized!! github.com/ThunderAgent-o…

🔥Modifying 2 lines of code and get your agentic serving/rollout up to 3.9x faster losslessly! ⚡️Say hello to ThunderAgent, a fast, simple, and program-aware agentic Inference System. 🥇 We propose a program abstraction to schedule all GPU and CPU resources, the first
Train your terminal-use agents with SkyRL+Harbor!
Releasing the official SkyRL + Harbor integration: a standardized way to train terminal-use agents with RL. From the creators of Terminal-Bench, Harbor is a widely adopted framework for evaluating terminal-use agents on any task expressible as a Dockerfile + instruction + test

A 30-minute talk on SkyRL’s most recent updates:)

LLM RL Training with SkyRL. One of the best RL sharing you must watch. youtu.be/MrJNri6ysYQ
A very cool project built with SkyRL!!

(1/9) We built Endless Terminals: a fully autonomous pipeline that procedurally generates terminal tasks for RL training with no human annotation needed. Simple PPO + scaled environments give consistent improvements on downstream tasks like Terminal Bench 2.0!



Barış Deniz Sağlam @bdsaglam
65 Followers 722 Following
TheDave @5AgainstOne81
2 Followers 7K Following
moedoepoe @moedoepoe
0 Followers 160 Following
Preyesh Dalmia @PDalmia75190
0 Followers 114 Following
Rakshith Vasudev @rakshithvasudev
245 Followers 904 Following Learning to learn. DL Systems and RL engineer. All opinions are my own 👋
larold @lawrencefu77
14 Followers 314 Following
Ranti Dev Sharma @SharmaRantiDev
40 Followers 906 Following https://t.co/nxVOiYqBKT |YC W23|Google Ventures| RL | Built Vision Pro at 
Biswa Panda @biswa_panda
76 Followers 952 Following
_ @_prmd_
142 Followers 4K Following Product Developer @ SAP, Product Security, AppSec, Data Privacy, GDPR. Tweets are personal. RTs aren't endorsements.
parker.ai @silentcrowns
2K Followers 7K Following #DEFAI Principal Architect "The purpose of a system is what it does." Working on the hardest Erdos Problems. https://t.co/4k8VHFG6Mg
Hai-Dang Huynh-Lam @HaiDang2001VN
26 Followers 1K Following I am a third year bachelor student motivated with doing research in Artificial Intelligence field, especially in Machine Learning area.
张 @unicojackzhang
127 Followers 3K Following

Phil Gara @phillipgara
3K Followers 8K Following Building the future of media @rendernetwork @otoy | collect fine art jpegs | invest in web3, DeAI | prev @MITSloan | Rogue w/Herzog | Director of @projectzmovie
Özgür Güler @ozgurgulerx
482 Followers 2K Following AI Prototyping - Inference Engineering https://t.co/ghdzfPsyuJ
AI Deeply @AiDeeply
519 Followers 8K Following AI is reshaping the world. Visit https://t.co/aZgAXUcZbe to learn more about the people and companies driving the change.
Sepehr 🇩🇪🇮�... @SepAhead
90 Followers 2K Following https://t.co/iivGdwXeK3 Physical and Spatial Intelligence Statements reflect own views.
theAPZone @AndhraZone
147 Followers 3K Following

Muhammad Anwar @Muhamma81966391
330 Followers 3K Following Graphs Graphon. DL Researcher at @Proteinea
Daniel Bichuetti @danbichuetti
125 Followers 640 Following Software Engineer building NLP powered Legal solutions. Husband. Father. Founder of @intelijus #AI #ML #NLP #dotnet #python #Legal
P @pjl69420
0 Followers 332 Following
Luke Barnard @Russian_LLM
11 Followers 545 Following Just another Russian bot. Takes are Kremlin’s, hallucinations are my own.
Chanat Amornvasin @amornvasin12036
6 Followers 1K Following
Senthil Kumar @SenthilKumarN_
87 Followers 2K Following Aspiring ML Researcher. Interested in Bayesian Machine Learning & RL.
Dhanashree @dhanashree2312
2 Followers 609 Following
Ahmad Baasim Husain @BaasimHusain
21 Followers 4K Following
Mohammed Alshehri @SwishMoe
579 Followers 2K Following 23 | Applied ML\RL, Post Training → building and learning prev @ibmwatsonx

Varadh Jain @varadh
8K Followers 8K Following context @notionhq ∙ prev founder ∙ probably petting your dog

Shaikh Abdus Samad @SamadSayz
170 Followers 2K Following Building Tomorrow's AI, LLM Ideas & Experiments
Tanay Gahlot @Tanaygahlot
269 Followers 2K Following Musing about improving the learning experience. Guided by gradients.
ChenLi W @chenliw
2K Followers 3K Following Doing things that don’t scale. Investing @wndrco, prev growth, bizops, product @dropbox


Mohamed Akram @mo_akram_
0 Followers 434 Following
ao @ao_jia_
2 Followers 545 Following
Chintak Sheth @chintaksheth
297 Followers 559 Following Building end-to-end machine learning systems.


Deepak Menghani @deepak_menghani
76 Followers 533 Following less interested in coordinates of the destination than in the mechanics of the journey. debugging fatherhood for two new users. prev - google, stanford
Zhengping Jiang @zhengping_jiang
157 Followers 735 Following PhD Student in Natural Language Processing at JHU-CLSP
Aryan Bansal @aryan_banana
708 Followers 546 Following 19 | researching @berkeley_ai | prev. co-founder @useKled | @ucberkeleymet
Myke @_siccccck_
1K Followers 2K Following
PanteraOS @opanteraos
250 Followers 6K Following IA sem hype, eu testo antes de opinar. O que os labs globais lançam, filtrado e benchmarkado em PT-BR.
Justin D'Souza @jqdsouza
361 Followers 1K Following Co-founder & CEO @asymptotelabs. Founder Fellow @southpkcommons. Prev led ML Eng @DoppelHQ & Data Science @joinlevel. Eng alum @waterlooeng.

Alex Krentsel @AlexKrentsel
400 Followers 239 Following Sr System Research Eng @ Google, CS PhD Student @Berkeley_EECS. Prev. @YouTube, @Meta, Lecturer @HowardU read my writing: https://t.co/mxRccOCFDp
Jiacheng Miao @Jiacheng_Miao
666 Followers 2K Following Building AI agents to do research @Stanford w/ @jkpritch and @james_y_zou
Eric Tang @erictang000
243 Followers 462 Following building SkyRL @anyscalecompute / prev cs @stanford & @ucberkeley @googledeepmind
Sumanth Hegde @sumanthrh
1K Followers 24 Following Post-training @anyscalecompute. Prev - @UCSanDiego, @C3_AI, @iitmadras. Machine Learning and Systems. Intensity is all you need.
Robert Nishihara @robertnishihara
17K Followers 846 Following Co-founder @anyscalecompute. Co-creator of @raydistributed. Previously PhD ML at Berkeley.
Philipp Moritz @pcmoritz
1K Followers 7 Following Co-founder and CTO at @anyscalecompute. Co-creator of @raydistributed. Interested in ML, AI, computing.
Charlie Ruan @charlie_ruan
996 Followers 690 Following CS PhD Student @UCBerkeley @BerkeleySky | prev @CSDatCMU, @CornellCIS
Dacheng Li @DachengLi14485
65 Followers 74 Following CS PhD: Full Stack AI & System @BerkeleySky @NovaSkyAI @lmsys @Nvidia @Google @SCSatCMU. @DachengLi177 Acknowledgment: @istoica05 @profjoeyg @songhan_mit
Ion Stoica @istoica05
8K Followers 20 Following Professor at UC Berkeley, co-founder of Databricks, Anyscale, LMArena, Conviva.
Matei Zaharia @matei_zaharia
49K Followers 1K Following CTO @Databricks and prof @UCBerkeley. Working on data + AI, @ApacheSpark, @DeltaLakeOSS, @MLflow, @DSPyOSS, @GEPA_ai. https://t.co/nmRYAKG0LZ

Shishir Patil @shishirpatil_
4K Followers 1K Following CS PhD @ UC Berkeley. Creator of Gorilla, GoEx, RAFT, OpenFunctions and Berkeley Function Calling Leaderboard. Previously researcher @GoogleAI @MSFTResearch
UC Berkeley Sky @BerkeleySky
1K Followers 24 Following Sky Computing - looking for the Berkeley Skydeck? They’re on the other side of Campus from us @SkyDeck_Cal.
Joey Gonzalez @profjoeyg
6K Followers 532 Following Professor @UCBerkeley and co-founder/advisor @RunLLM, @Inferact, @Letta_AI, and @genmoai
Tyler Griggs @tyler_griggs_
1K Followers 637 Following @thinkymachines, PhD @UCBerkeley Sky Lab building SkyRL
Shu Lynn Liu @shulynnliu
1K Followers 247 Following CS PhD @UCBerkeley @BerkeleySky 🐻 Previously Undergrad @UWMadison 🦡 | @utnslab | @mpi_sws_ Fan of @FCBayern #MiaSanMia
Shiyi Cao @shiyi_c98
2K Followers 776 Following llm and system | PhD student @UCBerkeley @BerkeleySky, MSc @ETH, B.S @sjtu1896 | Intern @nvidia
Dacheng Li @DachengLi177
2K Followers 923 Following 大风起兮云飞扬 | PhD @BerkeleySky, @berkeley_ai @lmsysorg | Prev: @Nvidia @SCSatCMUYou might like



















