

SecureBio @SecureBio
SecureBio is a research non-profit that works to advance biotechnology safely and prevent catastrophic pandemics securebio.org Joined January 2025-
Tweets168
-
Followers611
-
Following1
-
Likes8
Why run AI biorisk evals at all? In his new post, @JasperGeh explains the biorisk evidence hierarchy (first-principles arguments, evals, uplift RCTs) and why evals provide the best evidence-per-dollar. Read the full post here: securebio.substack.com/p/the-role-of-…

We need to take AI biorisks equally seriously while we still have time to act: pre-deployment evaluations, third-party red-teaming, and managed access are low-friction ways to better understand and manage biorisks posed by advanced AI. The trendline is clear: biological capabilities of frontier AI are increasing, and unless we improve the biosecurity of these models, the risks of bio-incidents will grow. We need to secure the downside of these models, in order to preserve their upside.
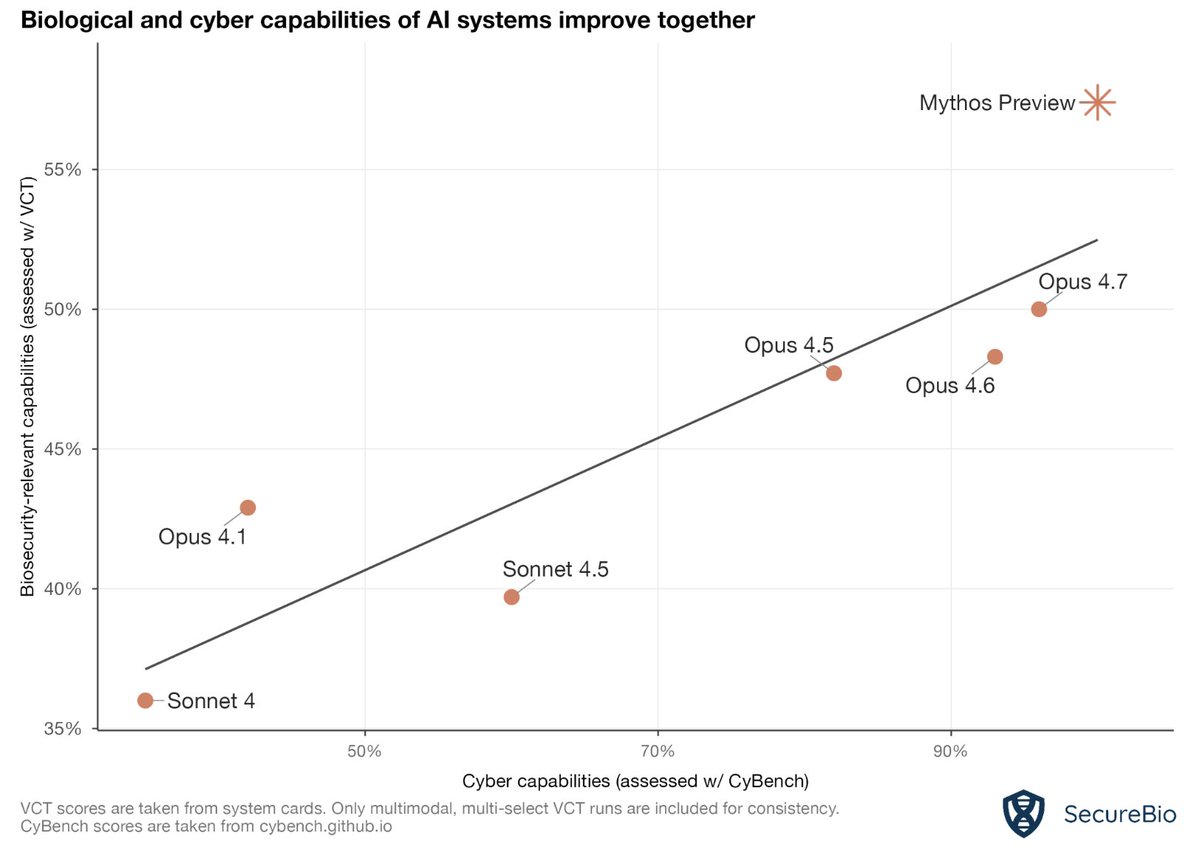
Bio and cyber AI capabilities increase together. Claude Mythos scored higher than any other model on CyBench, an evaluation of cybersecurity capabilities. It also scores higher than any other model (and 100% of human experts) on our Virology Capabilities Test, which measures advanced lab troubleshooting capabilities. Not only that, but Mythos showed the greatest score increase we’ve ever observed.
Our attention to biorisks posed by AI needs to match the current attention given to cyber-risks. The staged release of Claude Mythos in order to bolster defenses in key industries is necessary to shore up resilience against a new class of cyber-risk across critical industries. We should do the same with biorisks.

Between Mythos, Anthropic v Pentagon, and the drumbeat of biosecurity concerns, I think we're entering a period where (a) AI as a consumer product (chatbot + coding assistant) will continue to behave like a "normal" technology—a very powerful tool that does all sorts of useful


Very glad to see government officials at the highest level taking the threat of AI-engineered bioweapons seriously


NEWS from my @WSJopinion interview with @SecScottBessent Treasury officials say that at the Trump-Xi summit in Beijing next month, history will be made. For the first time ever, the leaders of earth’s two greatest powers will discuss AI as an agenda item. Messrs. Trump and Xi

Glad to see AI bio-risk entering the public consciousness. It really is existential.
Between Mythos, Anthropic v Pentagon, and the drumbeat of biosecurity concerns, I think we're entering a period where (a) AI as a consumer product (chatbot + coding assistant) will continue to behave like a "normal" technology—a very powerful tool that does all sorts of useful
@AndrewButchart1 @TylerAStepke Good question! We don't think models been have trained on the test data. VCT is not publicly posted and we use canary strings for firms to remove leaks. Also, we check models for being able to complete strings from the benchmark. Also we've kept holdout sets for checking too.
We at SecureBio tested GPT-5.5’s biorisk-related capabilities: virology and pathogen knowledge, niche scientific knowledge, agentic bio capabilities, and bio AI tool usage. GPT-5.5 scores at or near the top on all of the evaluations we gave it. Some highlights:

Many thanks to the OpenAI team for engaging with us on pre-release testing! Our full results and methodology are described in this report: substack.com/home/post/p-19…
3rd party pre-release testing like this is vital to understand how biosecurity-relevant capabilities are evolving and to ensure that safeguards, evaluations, and policy responses keep pace before these models reach the public.
Both algorithms flag COVID, but with ~100x more reads that match the conserved portion of the genome than cross the discontinuities, Clades of Concern would likely trigger when 1% as many people had been infected. Full post: securebio.org/blog/would-thi…
If that algorithm were unavailable, it would have been flagged by Chimera Detection, which flags sequencing reads where only a portion matches a known pathogen. The discontinuities are at positions 21,697 and 23,074, and CD would flag reads crossing those points.
When we explain the algorithms we use to analyze untargeted metagenomic sequencing data people always ask: would this have flagged COVID? The answer is yes, but the details explain a lot about how detection works.
Over the winter we hired several people across the org: * Alessandro Zulli (Zephyr lead) * Jo Faraguna (Bioinformatics Engineer) * Jake Lloyd (Research Associate) * Jared Gurzenda (Senior Research Associate) * Matt Benczkowski (Associate Scientist) More details: securebio.org/blog/updates-m…
In collaboration with SecureBio's AI team we automated initial human review of flags. LLMs get sequencing reads, bioinformatic annotation, the ability to query BLAST to query databases, and a clear rubric, and they handle clear-cut cases well. Human review load is down ~80%.
SecureBio Detection has a lot to share since our last update: several new preprints on our wastewater work, scaled up our nasal swab collection dramatically, we're moving into a larger lab space, and we've rebranded from the "Nucleic Acid Observatory" to "SecureBio Detection" More details: securebio.org/blog/updates-m…

IBBIS @IBBIS_bio
169 Followers 157 Following Safeguarding modern bioscience and biotechnology so it can advance and flourish safely and responsibly.
Yuvraj Singh Ashiya @ashiya_yuvraj
0 Followers 4K Following Re-tweets are not endorsements.and the best teacher is your last mistake.
Hannu Rajaniemi @hannu
7K Followers 1K Following Co-founder and CEO of @HelixNano. Co-founder / board member @redqueenbio. Author of The Quantum Thief series, Summerland and DARKOME https://t.co/o6RsVIAzHD
None @gstendig
5 Followers 909 Following
Dr. Bogdan Petkovic @whydoIexist713
20 Followers 2K Following when life gives you lemons, make an omelette.

Emre Yavuz @_emreyavuz
59 Followers 473 Following
JennynNYNY @NynyJennyn
106 Followers 3K Following
AL @bananalove503
135 Followers 2K Following you can call me AL. mostly here to live out my childhood dream of being a CFB reporter: 🦆& 🦫 & Zers 🖤❤️ science tho 🧪. it’s 2026 be nice, duh.
Osinetop @osinetop69952
27 Followers 1K Following
Jason Asher @jason_m_asher
19 Followers 184 Following
Molla Knudson 😷�... @KnudsonMolla
119 Followers 587 Following Do not go back with life's choices, keep moving forward 📶 🔸 #Patience 🔸 #Voter. 🔸 #MaskWearer 🔸 #Observer ▫️ #SportsFan ▫️ Seven7Iron
1234 @septdvatsyadva
1 Followers 3K Following
SC @shoshacapps
212 Followers 3K Following



Interlocuteur @Interlocateur
5K Followers 7K Following 🩺 🇺🇲 Eclectic, Information-oriented. Researcher. Science, Health, Faith, Nature, ForeignPolicy. 🇮🇱 Integrity is a must.
L Martin @lainemartin1
132 Followers 2K Following
Richard Ren @notRichardRen
571 Followers 588 Following Working on catastrophic AI risks. Research scientist & engineer @CAIS
Spring Tulip @SpringTulip000
10K Followers 63 Following

Anthony Fries @Freezer18mu
180 Followers 1K Following Biologist, Birder, Scientist at the United States Air Force Research Laboratory
Valérie Peloux @escuchoco13
10 Followers 242 Following
Ju @justillhere
248 Followers 1K Following Pissed off RN - Still 😷. Posts mostly about public health, animals and politics. I know , weird. Neuro🌶️. #NAFO
issa ndagi umaru @issa_ndagi
10 Followers 198 Following
Dr. Ricardo Delgado @Ricardo24382506
192 Followers 685 Following Ingeniero Agrónomo, MSc, PhD. Plant pathologist - Fitopatologo 🇪🇨🇺🇸 🍌🥔🍫🌾🔬
Erin Prater, MPH, M.A... @ErinMPrater
3K Followers 2K Following Senior science writer, health educator, @ucsdstemcell. Formerly @fortunemagazine. https://t.co/rPCziiucwh #T1D #raredz #dxodyssey #neurodiversity #actuallyautistic

TorqueCapital @TorqCap
12 Followers 214 Following
Denise T G 13 @bluebloodguru
335 Followers 1K Following Dynamic muse, healer and inspiration for a chosen few. @TheEDSociety certified patient/community advocate.🦓 @Cornell Medicinal Plants Certificate.🌱
Billy Becker @thenetmonkey
2K Followers 4K Following ex-twitterSRE "I have approximate knowledge of many things"
R. Smithrandal @1smithrandal
252 Followers 977 Following En route to our planetary collapse, distracted by painting, architecture, classical Chinese, horticulture, films--well, almost everything. Former HCW. She/her
Existential Crisis Pa... @crisis_parade
123 Followers 682 Following Cathartic if you have depression, probably pretty awkward if you don't..
Rachelle Brown @RachelleB93639
11 Followers 72 Following
GheeButtersnaps @GheeButtersn
171 Followers 1K Following Pro-White, Anti-Communist, Crime stat enjoyer, Noticer, and Hobbyist game developer.
Frosty @frostyxlt
13 Followers 157 Following
Roselyn Martin @roslmartin
47K Followers 23K Following American 🇺🇸 (via Mexico🇲🇽) | Molecular oncologist | AI developer | Twice awardee from @harvardchansph | Devout Catholic
Paul says Mask It or ... @idealust
2K Followers 4K Following We are a deeply unserious species. Not even sure what else to say. Plan for tomorrow. Enjoy today. And help out your local communities.
Karin Lightstone @karinlightstone
362 Followers 4K Following dreamer, poet, enthusiast. another world is possible. she/her
Kelli Morgan @KelliMorganX
293 Followers 5K Following Writer | Founder | Fellow, Tiny 4.0, Viber, @SheFiOrg



Actuality News @_ActualityNews
13 Followers 404 Following The news, without the noise. https://t.co/2Jpzs5j7Un
blue dot @bluedot64354565
1 Followers 1K Following
Okra_King @calvtif
85 Followers 1K Following
GraySweatshirt @AnyAnagram
1K Followers 3K Following Doing what I can to stop illnesses, data centers, and genocides.
James Hulce @jchulce
151 Followers 1K Following Telecom infrastructure nerd & student at @tesu_edu. Opinions here are my own.
Katy @30Evergreen
32 Followers 2K Following
Marc Johnson @SolidEvidence
40K Followers 151 Following Molecular virologist, Professor, and wastewater detective. Same handle on bsky. Opinions are my own and do not reflect those of my employer or anyone else.You might like



















