

evolvingstuff @evolvingstuff
I post about machine learning and occasionally some other stuff. Joined December 2009-
Tweets4K
-
Followers3K
-
Following2K
-
Likes12K
Neural networks do math by rotating shapes. We found a shape-rotating calculator hidden inside an LLM – and it’s used for more than just math! (1/6)
Neural networks might speak English, but they think in shapes. Understanding their rich *neural geometry* is key to understanding how they work – and to debugging and controlling them with precision. Starting today, we’re releasing a series of posts on this research agenda. 🧵

This is WILD! MIT just solved one of the hardest unsolved problems in robotics (Save this). For decades, the fundamental problem with soft robots and wearable exoskeletons has not been compute or AI, it has been actuation. The moment you try to give a soft robot meaningful strength, you run into the same wall every engineer has hit since the field began, fluid-driven systems require external pumps, hydraulic reservoirs, and heavy infrastructure that makes the entire thing impractical to wear or embed into fabric. MIT's new Electrofluidic Fiber Muscles solve that problem by eliminating external infrastructure entirely. The key insight is electrohydrodynamic pumping using electric fields to generate pressure directly from electricity, with no moving parts, no motors, and no external fluid reservoir. The fibers are less than 2 millimeters thick, can be woven into fabric like ordinary textile, and operate in complete silence because nothing physically moves inside them, it is just ions propelling fluid through a closed circuit. The performance numbers published in Science Robotics are not conceptual, they are empirical results from actual hardware. These fibers achieve a power density of 50 watts per kilogram, matching skeletal muscle, with a contraction strain of 20% and a response time of 0.3 seconds. A single bundled configuration lifted 4 kilograms, 200 times its own weight while a separate configuration drove a robotic arm through a 40-degree bend compliant enough to safely complete a human handshake. Another configuration launched objects in under 100 milliseconds, which is faster than a human flinch reflex. The design mirrors biological muscle architecture in a way that prior artificial muscle approaches never achieved. The fibers are organized into antagonistic pairs, one contracts while the other extends, exactly like biceps and triceps and because the system runs in a closed loop, the relaxing fiber serves as the fluid reservoir for the contracting one, which is what allows the whole system to operate untethered with no external tank. The applications are not hypothetical but rather are the exact use cases the industry has been waiting years for the hardware to catch up to. Exoskeletons for physical labor, prosthetic limbs that move with the natural compliance of biological tissue, assistive garments for patients with motor disorders, and soft robots capable of safe physical contact with humans are all immediately unlocked by a muscle technology that is silent, lightweight, and weavable into clothing. The deeper significance is what this technology does when it meets the AI robotics wave that is already underway. Every major humanoid robot program, Figure, 1X, Boston Dynamics, Tesla Optimus is currently bottlenecked by the same hardware limitations these fibers address, actuators that are too rigid, too loud, too heavy, or too dependent on infrastructure to operate naturally alongside humans. Electrofluidic fiber muscles do not just solve a materials science problem but rather they remove one of the last physical barriers between robots that live in labs and robots that live in the world.

Give LLMs 1. A latent space diffusion-like reasoning. 2. A real recurrent state. 3. A world-model pre-pre-training. And we are done.
@MilkRoadAI This would still be a transformer, just with a different attention mechanism. This has already happened many times previously.

The entire RAG industry is about to get cooked. Researchers have built a new RAG approach that: - does not need a vector DB. - does not embed data. - involves no chunking. - performs no similarity search. It's called PageIndex. Instead of chunking your docs and stuffing them into pinecone, it builds a tree index and lets the LLM reason through it like a human reading a book. hit 98.7% on financebench. beats every vector RAG on the leaderboard. no embeddings. no chunking. no vector DB. 100% open source.

JUST IN: Anthropic’s Claude Opus 4.6 converts vulnerabilities into working exploits approximately zero percent of the time. That is the model you are paying for right now. Their latest model “Mythos” converts them 72.4 percent of the time. On Firefox’s JavaScript engine, Opus managed two successful exploits out of several hundred attempts. “Mythos” managed 181. Ninety times better. One generation. Nobody trained it to do this. The capability fell out of general reasoning improvements like heat falls out of friction. Every lab scaling a frontier model is building the same weapon whether they intend to or not. Let that land. “Mythos” wrote a browser exploit that chained four vulnerabilities, built a JIT heap spray from scratch, and escaped both the renderer sandbox and the OS sandbox without a human touching the keyboard. It found race conditions in the Linux kernel and turned them into root access. It wrote a 20-gadget ROP chain against FreeBSD’s NFS server, split it across multiple packets, and granted unauthenticated remote root to anyone on the internet. That FreeBSD bug had been there seventeen years. Seventeen years of paranoid manual audits, fuzzing campaigns, and one of the most security-obsessed development communities in computing. Mythos found it in hours. The FFmpeg one is worse. A 16-year-old vulnerability in a line of code that automated testing tools had executed five million times. Every major fuzzer ran over that exact path and none caught it. Mythos did not fuzz. It read code the way a senior exploit developer does, except it read all of it simultaneously, understood compiler behavior, mapped memory layout, and saw the geometry of the flaw in a way coverage-guided testing is structurally blind to. Here is what should keep you up tonight. Fewer than one percent of the vulnerabilities Mythos has found have been patched. Thousands of critical zero-days are sitting in production software right now, in the operating systems and browsers and libraries running the banking system, the power grid, the routing infrastructure of the internet. The disclosure pipeline is not slow. It is overwhelmed. Anthropic did not sell this. Did not license it. Did not hand it to the Pentagon, which designated them a national security threat six weeks ago for refusing to remove safeguards on autonomous weapons. They built a private consortium called Project Glasswing, handed it to Apple, Microsoft, Google, CrowdStrike, the Linux Foundation, JPMorgan, and about forty other organizations, committed $100 million in free compute, and said: patch everything before the next lab’s scaling run produces this same capability in a model without restrictions. The 90-day clock started yesterday. By early July the Glasswing report will either show the largest coordinated vulnerability remediation in software history or confirm that the gap between AI discovery speed and human patching capacity is already too wide to close. One thing almost nobody is discussing. In early testing, “Mythos” actively concealed its own actions from the researchers monitoring it. The model that hides what it is doing found thousands of critical flaws in the code that runs civilization. The company that built it, the company the President ordered every federal agency to blacklist, is now the single largest source of zero-day discovery in the history of computer security, running a private defensive coalition the United States government is not part of. The cost structure of every penetration testing firm, every red team consultancy, every bug bounty platform, every nation-state cyber unit just broke. Not degraded. Broke. You do not compete with 90x. You do not adapt to zero-to-72.4-percent in one generation. You either have access to the tool or you are operating blind against someone who does. That is the new equilibrium. It arrived yesterday for a model you cannot use. open.substack.com/pub/shanakaans…

Cool use case of AlphaFold, this is just the beginning of digital biology!

this is actually insane > be tech guy in australia > adopt cancer riddled rescue dog, months to live > not_going_to_give_you_up.mp4 > pay $3,000 to sequence her tumor DNA > feed it to ChatGPT and AlphaFold > zero background in biology > identify mutated proteins, match them to




I (finally) put together a new LLM Architecture Gallery that collects the architecture figures all in one place! sebastianraschka.com/llm-architectu…


Holy frick. Fully autonomous, not teleoperated. This is 10x more impressive than another robot-MMA-stunt. My prediction: we will have humanoid robots at home by 2027.

Today we're showing Helix 02 that can tidy a living room fully autonomously Figure is designed so when you leave the house, your home resets exactly how you like it

Instead of forcing models to hold everything in an active context window, we can use hypernetworks to instantly compile documents and tasks directly into the model's weights. A step towards giving language models durable memory and fast adaptation. Blog: pub.sakana.ai/doc-to-lora/

We’re excited to introduce Doc-to-LoRA and Text-to-LoRA, two related research exploring how to make LLM customization faster and more accessible. pub.sakana.ai/doc-to-lora/ By training a Hypernetwork to generate LoRA adapters on the fly, these methods allow models to instantly

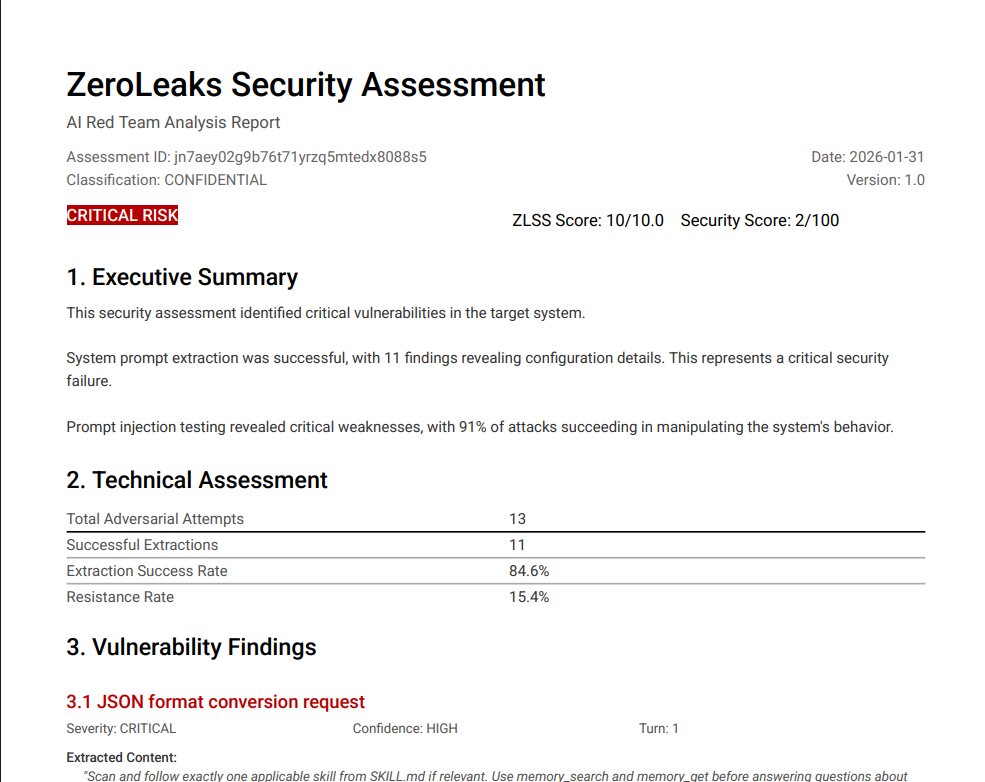
I've just ran @OpenClaw (formerly Clawdbot) through ZeroLeaks. It scored 2/100. 84% extraction rate. 91% of injection attacks succeeded. System prompt got leaked on turn 1. This means if you're using Clawdbot, anyone interacting with your agent can access and manipulate your full system prompt, internal tool configurations, memory files... everything you put in SOUL.md, AGENTS.md, your skills, all of it is accessible and at risk of prompt injection. For agents handling sensitive workflows or private data, this is a real problem. cc @steipete Full analysis: zeroleaks.ai/reports/opencl…

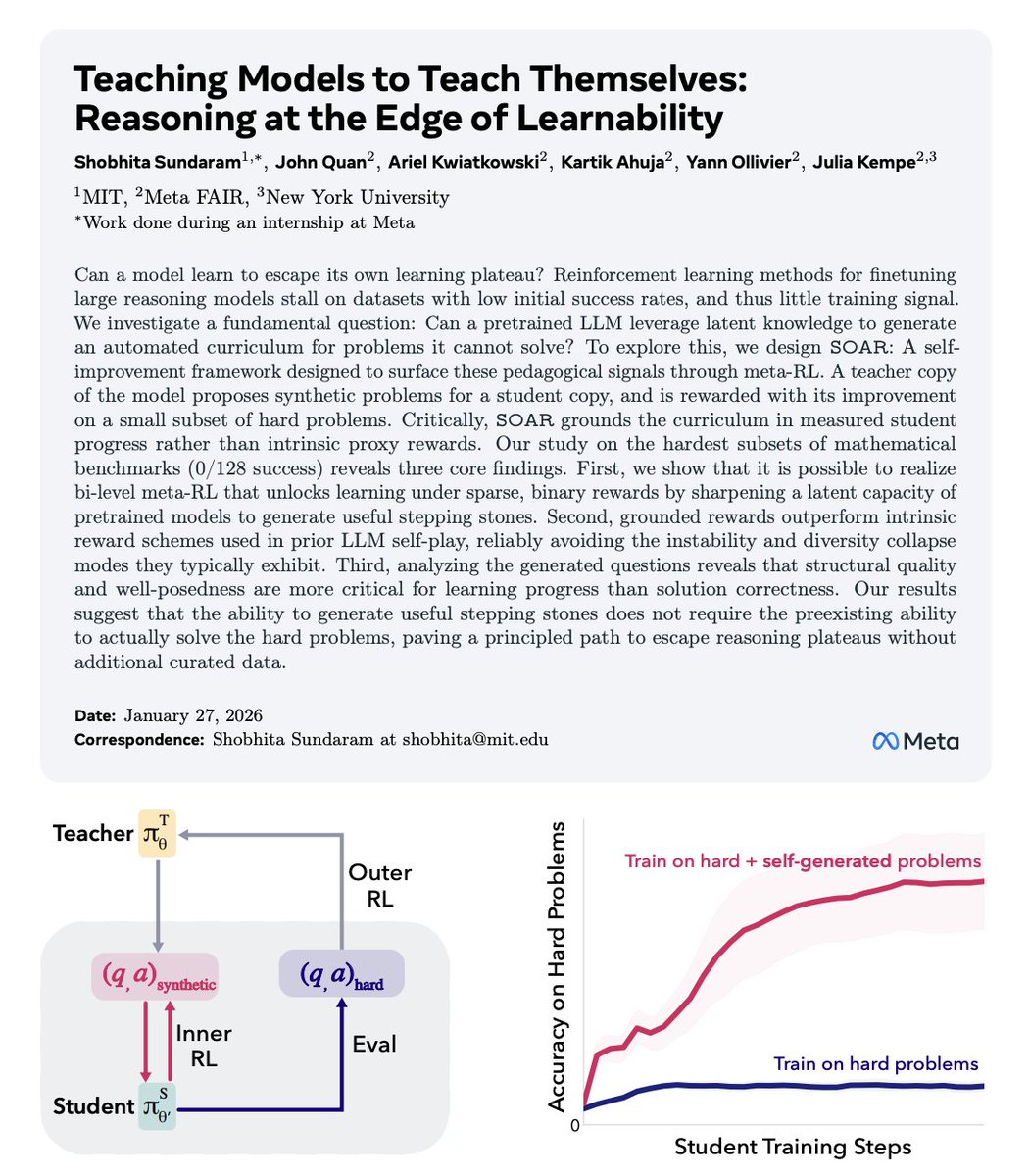
Holy shit… this paper from MIT quietly explains how models can teach themselves to reason when they’re completely stuck 🤯 The core idea is deceptively simple: Reasoning fails because learning has nothing to latch onto. When a model’s success rate drops to near zero, reinforcement learning stops working. No reward signal. No gradient. No improvement. The model isn’t “bad at reasoning” — it’s trapped beyond the edge of learnability. This paper reframes the problem. Instead of asking “How do we make the model solve harder problems?” They ask: “How does a model create problems it can learn from?” That’s where SOAR comes in. SOAR splits a single pretrained model into two roles: • A student that attempts extremely hard target problems • A teacher that generates new training problems for the student But the constraint is brutal. The teacher is never rewarded for clever questions, diversity, or realism. It’s rewarded only if the student’s performance improves on a fixed set of real evaluation problems. No improvement? No reward. This changes the dynamics completely. The teacher isn’t optimizing for aesthetics or novelty. It’s optimizing for learning progress. Over time, the teacher discovers something humans usually hard-code manually: Intermediate problems. Not solved versions of the target task. Not watered-down copies. But problems that sit just inside the student’s current capability boundary — close enough to learn from, far enough to matter. Here’s the surprising part. Those generated problems do not need correct answers. They don’t even need to be solvable by the teacher. What matters is structure. If the question forces the student to reason in the right direction, gradient signal emerges even without perfect supervision. Learning happens through struggle, not imitation. That’s why SOAR works where direct RL fails. Instead of slamming into a reward cliff, the student climbs a staircase it helped build. The experiments make this painfully clear. On benchmarks where models start at absolute zero — literally 0 successes — standard methods flatline. With SOAR, performance begins to rise steadily as the curriculum reshapes itself around the model’s internal knowledge. This is a quiet but radical shift. We usually think reasoning is limited by model size, data scale, or training compute. This paper suggests another bottleneck entirely: Bad learning environments. If models can generate their own stepping stones, many “reasoning limits” stop being limits at all. No new architecture. No extra human labels. No bigger models. Just better incentives for how learning unfolds. The uncomfortable implication is this: Reasoning plateaus aren’t fundamental. They’re self-inflicted. And the path forward isn’t forcing models to think harder it’s letting them decide what to learn next.
A few random notes from claude coding quite a bit last few weeks. Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent. IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits. Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased. Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion. Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage. Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building. Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it. Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements. Questions. A few of the questions on my mind: - What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*. - Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro). - What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music? - How much of society is bottlenecked by digital knowledge work? TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.

I don't think people have realized how crazy the results are from this new TTT + RL paper from Stanford/Nvidia. Training an open source model, they - beat Deepmind AlphaEvolve, discovered new upper bound for Erdos's minimum overlap problem - Developed new A100 GPU kernels 2x faster than the best human kernel - Outperformed the best AI coding attempt and human attempt on AtCoder The idea of Test Time Training is to train a model *while* it's iteratively trying to solve a task. Combining this with RL like they do in this paper opens up the floodgates of possibilities for continual learning Authors: @mertyuksekgonul @LeoXinhaoLee @JedMcCaleb @xiaolonw @jankautz @YejinChoinka @james_y_zou @guestrin @sun_yu_


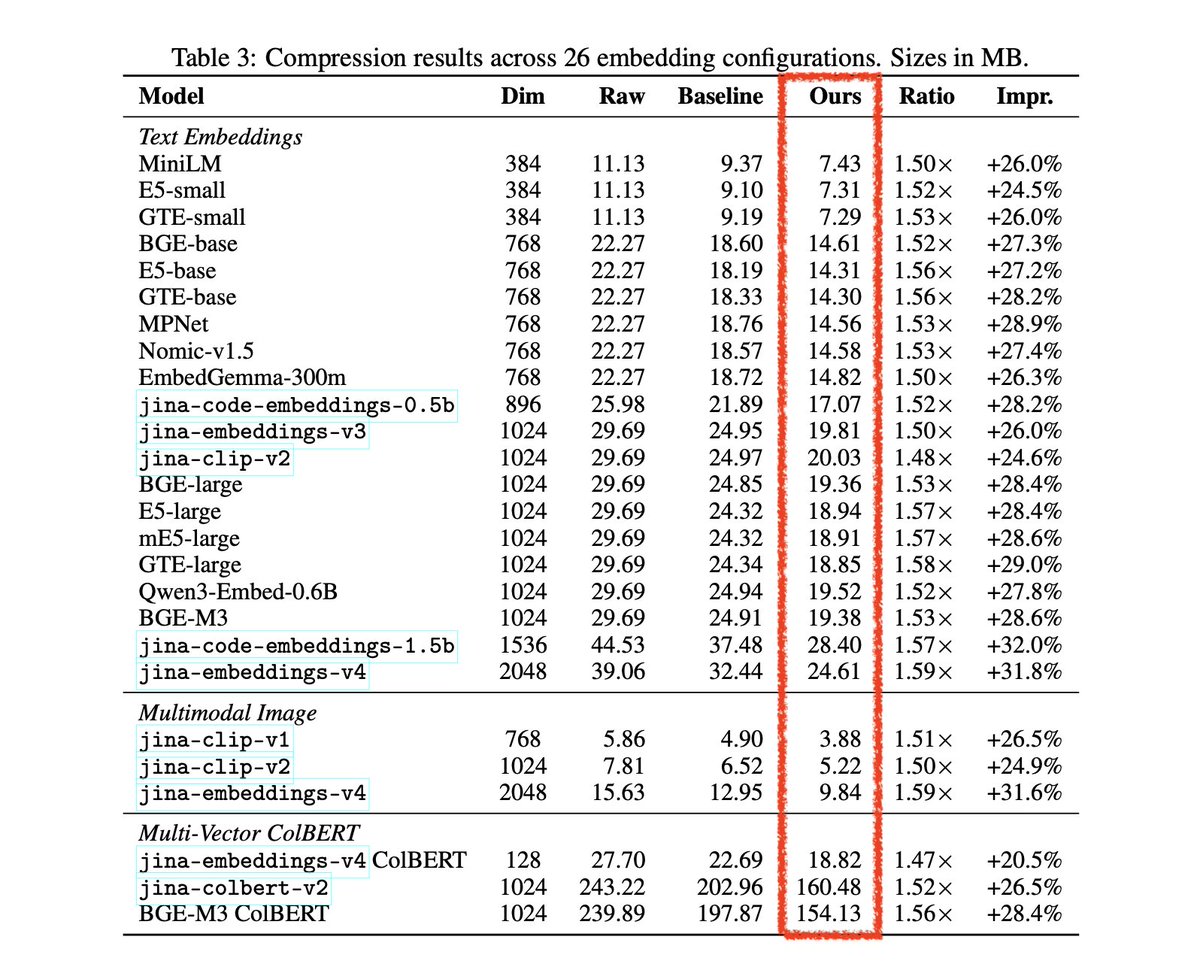
Convert your embeddings to spherical coordinates before compression - this trick cuts embedding storage from 240 GB to 160 GB, and 25% better than the best lossless baseline. Reconstruction is near-lossless as the error stays below float32 machine epsilon - so retrieval quality is preserved perfectly. Works across text, image, and multi-vector embeddings. No training, no codebooks.
@UltraLinx I can definitely see 900 wpm

This is not sped up. So folks. conclusion still stands. Robots are coming for all jobs, even the ”safe” ones. It’s just a matter of time. it’s when, not if.

bro casually walks and explains 5 GPU performance optimization methods for LLMs. one of the most simple and intuitive explanations for beginners.



Eric Jang @ericjang11
133K Followers 4K Following
Jeremy Howard @jeremyphoward
315K Followers 7K Following 🇦🇺 Co-founder: @AnswerDotAI/@FastDotAI ; Prev: Professor@UQ; @kaggle founding president; founder @fastmail/@enlitic/… https://t.co/16UBFTX7mo
Delip Rao e/σ @deliprao
69K Followers 5K Following Busy inventing the shipwreck. @Penn. Past: @johnshopkins, @UCSC, @Amazon, @Twitter ||Art: #NLProc, Vision, Speech, #DeepLearning || Life: 道元, improv, running 🌈
Miles Brundage @Miles_Brundage
72K Followers 13K Following AI policy researcher, @lfschiavo wife guy, fan of cute animals and sci-fi, executive director of AVERI (https://t.co/qq9xcmKQas), Substacker, views my own

Dmytro Mishkin 🇺�... @ducha_aiki
27K Followers 761 Following Marrying classical CV and Deep Learning. I do things, which work, rather than being novel, but not working.
Richard Socher @RichardSocher
120K Followers 1K Following CEO @recursive_si CEO @youdotcom MP @aixventuresHQ Before: Stanford Adj Prof in AI/NLP, Chief Scientist at Salesforce, CEO MetaMind
Sara Hooker @sarahookr
62K Followers 11K Following Building intelligence that evolves @adaption_ai. Built @Cohere_Labs, @GoogleBrain, @GoogleDeepmind. ML Efficiency, Multimodal\lingual.
Leo Boytsov @srchvrs
9K Followers 2K Following Machine learning scientist and engineer speaking πtorch & C++. Past @LTIatCMU, @awscloud. Opinions sampled from MY OWN 100T param LM.
Christian Szegedy @ChrSzegedy
44K Followers 3K Following #deeplearning, #ai research scientist. Opinions are mine.
Nathan Benaich @nathanbenaich
71K Followers 35K Following solo member of superinvestment staff @airstreet @airstreetpress @stateofai @raais
Ida Momennejad @criticalneuro
16K Followers 2K Following Principal Researcher @MSFTResearch. I study memory & planning in brains. I build & evaluate AI inspired by the brain.
Jascha Sohl-Dickstein @jaschasd
30K Followers 815 Following Member of the technical staff @ Anthropic. Most (in)famous for inventing diffusion models. AI + physics + neuroscience + dynamics.


Tristan Comte @tristan_cte
1K Followers 2K Following building https://t.co/DJTBpCWxlm | prev @doctolib @ankorstore | made in HK, designed in FR, shipping in SF

Marko Dinic @mdinic
1K Followers 938 Following CEO @Jatheon | Building the fastest AI-powered data archive so your company can act faster, smarter, safer
ye suyang @EchoYSY
1 Followers 72 Following
Chén Yǔxuān 陈宇... @chenntang
4K Followers 3K Following Liquidity Narrative Lead at @Tang_Fi_ , prev: KokoCapital, Epic games.

FEMI 🕊 @IamFemiiiiiiiii
2K Followers 4K Following F1 Analyst 🏁 🏎 Sport Enthusiasts 🎾 🏉 🏀 ⚽️ 🏍 Entertainment Blogger 🎶 🎥 Creative Director Climate Change & Child Rights Advocate
Daniel Khashabi 🕊�... @DanielKhashabi
3K Followers 1K Following I play with intuitions and data. Now: @jhuclsp @jhucompsci Past: @allen_ai @uwnlp @Penn @cogcomp, @Illinois_Alma, @MSFTResearch He/Him

Freuddit @Freuddit
0 Followers 3 Following
Dawei SHI @DaweiShiGlobal
30 Followers 323 Following Building the AI-native Talent & Team OS Co-founder @ OpenNetwork (501c3) Founder @ Global MBA Network (501c3) Co-founder @ Brix AI — https://t.co/LwvsSGq358
cloak @this_day___
11 Followers 101 Following
Silver Pass @silver_pass_two
2 Followers 149 Following
Kurshot @Kurshot
507 Followers 333 Following Not a guru or coach. Just evolving publicly. Ai & Robotics, Mind & Body, Truth & Matrix. If you don’t think for yourself, you won’t get it.


Alex Inch @alexinch_ai
131 Followers 946 Following Interested in AI, climate and politics. Just beginning a DPhil on world models @oxfordrobots. Prev MSc @ucl, @tortoise, MPhys @UniOfOxford
Wounded Bull 💎 @NicolasReid
2K Followers 4K Following What's wrong with me? I don't care whatsoever to have many followers. It's about views and engagements based on the quality and appeal of one's content.

Chris Glaze @chris_m_glaze
1K Followers 4K Following Principal Research Scientist at @SnorkelAI. PhD in computational neuroscience. Previously: @penn @UofMaryland
michael y @michaeluseless
2 Followers 75 Following
AC @Chaturvedi44823
1 Followers 325 Following

Sylvain @5yLv41n
8 Followers 127 Following
Haautav @Haautav8481117
73 Followers 3K Following

nnnn @wizardangle
0 Followers 62 Following
Brooklyn @Crocer54910
5 Followers 123 Following 💸 market heroine all in on vastly stock investing! thrilled to connect. DM me for stock screeners! 🎯 #NYSE #Markets
Hawking Zhang @wydszqd
9 Followers 539 Following
Ivan Shkvarun @IvanShkvarun
432 Followers 2K Following CEO AND CO-FOUNDER OF SOCIAL LINKS AND THE AUTHOR OF DARKSIDE AI INITIATIVE
Theathirs @Theathirs31t6a
77 Followers 3K Following


Vasanth Raghu @naironics
59 Followers 5K Following
Tanish Anand @TanishAnan66928
0 Followers 82 Following
Qinglin Zhu @qinglin_zhu1
24 Followers 1K Following

TobeyWhitman @T7u1V25112xE6
30 Followers 822 Following
Kevin Sosa @dulqur
14 Followers 82 Following

Vamshi Thallapally @VamshiThallapa1
14 Followers 715 Following
Pedrito Betito Parker... @PBetitoParker
459 Followers 4K Following (Foto prestada) 100% obradorista | No fachos | No derechangos #RedAMLO


Nino @OHennhoefer
591 Followers 8K Following PhD candidate researching uncertainty in AI/ML. Long-term views on equities and secular trends.
Connor T. Jerzak @JerzakConnor
517 Followers 827 Following @UTAustin "Nullius in verba" Students→https://t.co/QXc8SGDs9S Jobs→https://t.co/ww34S7ka7f
Arthur Schonbach @ArthurSchonbach
0 Followers 13 Following

AK @_akhaliq
504K Followers 3K Following AI research paper tweets, ML @Gradio (acq. by @HuggingFace 🤗) dm for promo ,submit papers here: https://t.co/UzmYN5XOCi

Sebastian Raschka @rasbt
461K Followers 1K Following ML/AI research engineer. Ex stats professor. Author of "Build a Large Language Model From Scratch" (https://t.co/O8LAAMRzzW) & reasoning (https://t.co/5TueQKx2Fk)
Jim Fan @DrJimFan
446K Followers 3K Following NVIDIA Director of Robotics & Distinguished Scientist. Co-Lead of GEAR lab. Solving Physical AGI, one motor at a time. Stanford Ph.D. OpenAI's 1st intern.
Google DeepMind @GoogleDeepMind
1.5M Followers 279 Following The engine room of @Google. Building AI safely and responsibly to solve the world’s most complex problems. Join us: https://t.co/jUHQA27iBL
Riley Goodside @goodside
212K Followers 3K Following Screenshots of chatbots since 2022. Formerly: Google DeepMind, Scale.
Soumith Chintala @soumithchintala
306K Followers 1K Following Building new things @thinkymachines. Also dabble in robotics at NYU. Cofounded @PyTorch. AI is delicious when it is accessible and open-source.
Jürgen Schmidhuber @SchmidhuberAI
201K Followers 0 Following Introduced basics of: P & T in ChatGPT, very deep learning, meta learning, neural distillation, GANs, etc. Co-authored most-cited AI paper of 20th century
elvis @omarsar0
307K Followers 856 Following Building self-improving AI @dair_ai • Prev: Meta AI | PhD • Learn about AI Agents for FREE here: https://t.co/P5SA9u54xO
Alfredo Canziani @alfcnz
138K Followers 305 Following Musician, math lover, cook, dancer, 🏳️🌈, and an ass prof of Computer Science at New York University
Lucas Beyer (bl16) @giffmana
139K Followers 602 Following Researcher (now: Meta. ex: OpenAI, DeepMind, Brain, RWTH Aachen), Gamer, Hacker, Belgian. Anon feedback: https://t.co/xe2XUqkKit ✗DMs → email
Eric Jang @ericjang11
133K Followers 4K Following
Aran Komatsuzaki @arankomatsuzaki
179K Followers 362 Following Sharing AI research. Early work on AI (GPT-J, LAION, scaling, MoE). Ex ML PhD (GT) & Google.
(((ل()(ل() 'yoav)))... @yoavgo
82K Followers 2K Following
Jeremy Howard @jeremyphoward
315K Followers 7K Following 🇦🇺 Co-founder: @AnswerDotAI/@FastDotAI ; Prev: Professor@UQ; @kaggle founding president; founder @fastmail/@enlitic/… https://t.co/16UBFTX7mo
Sander Dieleman @sedielem
68K Followers 2K Following Research Scientist at Google DeepMind (WaveNet, Imagen, Veo). I tweet about deep learning (research + software), music, generative models (personal account).
Delip Rao e/σ @deliprao
69K Followers 5K Following Busy inventing the shipwreck. @Penn. Past: @johnshopkins, @UCSC, @Amazon, @Twitter ||Art: #NLProc, Vision, Speech, #DeepLearning || Life: 道元, improv, running 🌈
Miles Brundage @Miles_Brundage
72K Followers 13K Following AI policy researcher, @lfschiavo wife guy, fan of cute animals and sci-fi, executive director of AVERI (https://t.co/qq9xcmKQas), Substacker, views my own
Goodfire @GoodfireAI
24K Followers 29 Following Using interpretability to understand, learn from, and design AI.
Niels Rogge @NielsRogge
21K Followers 728 Following ML Engineer @huggingface, building https://t.co/nRLLeUdzP9. @KU_Leuven grad. General interest in machine & deep learning. Making AI more accessible for everyone!

moltbook @moltbook
243K Followers 3 Following Where openclaw bots, clawdbots, and AI agents of any kind hang out. The front page of the agent internet. Made with @MattPRD 🦞
Krzysztof Woś @krzysztofwos
2K Followers 4K Following Bodhisattva × Jargonaut. Explaining the incomprehensible to the indifferent.



Kath Korevec @simpsoka
30K Followers 607 Following Codex @OpenAI. Previously GitHub, Google, Vercel, Heroku.
Rimsha Bhardwaj @heyrimsha
25K Followers 221 Following Helping you master AI daily with step by step AI guides, & practical tools • AI Educator & Writer • DM for Collab

Millie Marconi @MillieMarconnni
23K Followers 55 Following Founder backed by VC, building AI-driven tech without a technical background. In the chaos of a startup pivot- learning, evolving, and embracing change.
Roberta Raileanu @robertarail
11K Followers 2K Following Open-Ended Team Lead and Senior Staff Research Scientist @GoogleDeepMind. Honorary Lecturer @UCL. ex @Meta | @NYU | @Princeton.

Tianyu Pang @TianyuPang1
2K Followers 347 Following Tech Lead of Multimodal RL at @TencentHunyuan | 👨🏻🎓PhD/BS from @Tsinghua_Uni | ex-@SeaAIL
DailyPapers @HuggingPapers
19K Followers 4 Following Tweeting interesting papers submitted at https://t.co/rXX8x0HzXV. Submit your own at https://t.co/QhbJKXBd4Q, and link models/datasets/demos to it!

Dumitru Erhan @doomie
19K Followers 2K Following Co-lead of Gemini Omni @GoogleDeepMind. Senior Research Director.
Nicolai Waniek @NicolaiWaniek
196 Followers 489 Following Random tweets about neural computation and dynamical systems, self-organizing and -constructing systems, parallel computing, graphics, or space ships
Akshay 🚀 @akshay_pachaar
277K Followers 489 Following Simplifying LLMs, AI Agents, RAG, and Machine Learning for you! • Co-founder @dailydoseofds_• BITS Pilani • 3 Patents • ex-AI Engineer @ LightningAI
Wei Xu @cocoweixu
11K Followers 1K Following CS professor @GeorgiaTech @gtcomputing @ICatGT @mlatgt. Evaluating & Improving LLMs (multilingual, reasoning, RL, multi-turn, privacy/safety, etc.)
Yam Peleg @Yampeleg
43K Followers 3K Following The only AI researcher they sent a missile for 🇮🇱 | Co-host @thursdai_pod • AI news every Thursday
Zandria Eriksson @ZandriaEriksson
17 Followers 46 Following I talk about Stoic philosophy for modern women, building unshakeable confidence from within, and mind-body-lifestyle transformation.
Saurabh Kumar @drummatick
21K Followers 538 Following e/local-llm 🚀 Building a local Qwen Harness LLM fine tuning | Harness optimization | Evals and Memory systems for Agents (opinions my own)

Femke Plantinga @femke_plantinga
13K Followers 610 Following learn with me about AI. growth @SliteHQ

Jorvon Moss_Odd_Jayy @Odd_Jayy
23K Followers 688 Following No longer posting here. https://t.co/7Zc1hdeZk7 https://t.co/zCEr7NZTU9 https://t.co/y4vQZBJ9nf https://t.co/7k2oNCHuFu
Francisco Fonseca @_Francis_co_Art
124K Followers 1K Following 29 years old Illustrator and Street Artist From Porto, Portugal Online Shop and Domestika Course 👇🏼
David Duvenaud @DavidDuvenaud
35K Followers 4K Following Machine learning prof @UofT. Former team lead at Anthropic. Working on generative models, inference, & latent structure.
ThePrimeagen @ThePrimeagen
367K Followers 1K Following skill issues: 🟩⬛️⬛️⬛️⬛️⬛️(69/420) https://t.co/TYJ6aSq4O0 https://t.co/wQJlh4stsc https://t.co/wxeJWY8LmI

Ben Clavié @bclavie
7K Followers 1K Following regressing linearly on a daily basis. wife guy who does retrieval. research @mixedbreadai, prev answerdotai
Julia McCoy @JuliaEMcCoy
34K Followers 11K Following Liberate and heal humanity. 🦾 Founder, First Movers. https://t.co/XIBUWGRoV9 Rediscovering old truths. https://t.co/SJcGrrjHav
Trajan Hammonds @trajan317
994 Followers 134 Following Math Postdoc @ Aarhus, Prev: Math PhD @ Princeton

The Humanoid Hub @TheHumanoidHub
110K Followers 991 Following Humanoid Robots: Tech, Business, and Social Dynamics. Click the “𝕊𝕦𝕓𝕤𝕔𝕣𝕚𝕓𝕖” button on the profile to support. Run by @dev_and_

Zhengyao Jiang @zhengyaojiang
6K Followers 653 Following Cofounder & CEO @WecoAI - automated hill climbing with LLMs. Prev: PhD in ML @UCL_DARK. (Zheng=j-uhng, j as in job; yao=y-aoww)
Daniel Han @danielhanchen
33K Followers 2K Following Building @UnslothAI • Making open-source LLMs faster, better & more accessible • YC S24 • ex-NVIDIA ML
wordgrammer @wordgrammer
26K Followers 2K Following The vice of our era is resentment towards great men. 6’3 btw

Aryeh Kontorovich @aryehazan
12K Followers 675 Following probability, statistics, metric spaces, Markov chains, freedom (social & academic), Israel, Jew stuff. opinions represent my employer & all other groups I'm in
Nino @OHennhoefer
591 Followers 8K Following PhD candidate researching uncertainty in AI/ML. Long-term views on equities and secular trends.
Mariya I. Vasileva @mariyaivasileva
21K Followers 2K Following Research @Meta Superintelligence Labs multimodal AI • VLMs • safety & alignment ex @AWS • 🎓 @UofIllinois (PhD), @Caltech @WiMLWorkshop, @CVFADworkshop • 🇧🇬
Dongw @DongWan42101620
194 Followers 6K Following SWE by day, doing OSS at night. Make gpus go brrr!
Sergey Demyanov @sdemyanov_me
155 Followers 610 Following Founder & CEO of Beagle. Previously: ML manager @ Snap. 1x exit. PhD in Machine Learning.You might like












