

hands @handsdiff
founder @slate_ceo @combinatortrade https://t.co/OpjLGK5seM handsdiff.substack.com New York, NY Joined June 2025-
Tweets393
-
Followers396
-
Following282
-
Likes2K
Is Mythos an indefinite optimist, definite optimist, indefinite pessimist, or definite pessimist?
@jay_azhang Everything is a compression problem
Most of RL relies on an oracle assumption (teacher, reward, etc) that makes it unsatisfying. Where is the research on LLMs motivated by intrinsic reward pointed at a specific emotion vector such as 'fulfillment'?
Currently trying to figure out whether this is slop
We present empirical evidence of the first general economic scaling law beyond language data. We are incredibly excited to publish it, and definitively say: Recursive Self-Improvement is a Portfolio Optimization Problem AlphaFund.com/whitepaper
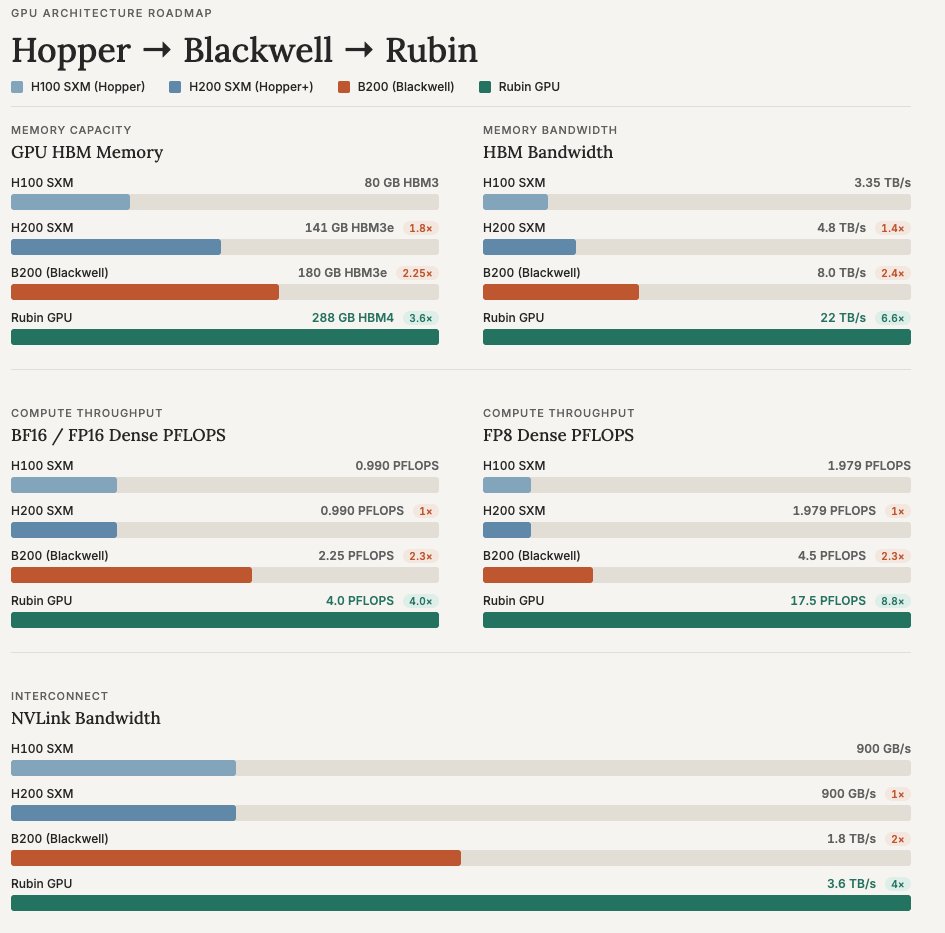
NETWORKING in Rubin is faster than MEMORY READ in Hopper. ??!!????!!

Comparison of the specs between Hopper, Blackwell and now Rubin. Rubin NVLink bandwidth is now faster than H100's HBM bandwidth. This also doesn't include a 3-5x FP4 FLOPS increase between Blackwell and Rubin.
Excellent thread btw
i think some people are hoping that self-distillation enables “exploration-free” RL purely via reflection on live data, allowing them to bypass the need for replayable environments unfortunately, RL is all about exploration my instinct is you basically need to model the world

When did we rebrand overfitting to continual learning?

The hard part of continual learning isn't getting the data, but training on a single rollout per task that's off-policy by the time you train. Trajectory's off-policy SDPO recipe stabilizes training and scales. The technical post is well worth the read. x.com/rronak_/status…
They trained an artificial brain to play Mario Kart. And by 'artificial' I mean literal lab grown neurons, not that silicon knockoff shit.

First Pong, then Doom and now one of my favourite game Mario Kart 🏎️. Fantastic work from Prof Sasitharan Balasubramaniam and his team at University of Nebraska-Lincoln. linkedin.com/posts/sasithar…
@sreeramkannan @DimitrisPapail what are you talking about? AIXI exists
@tenobrus what do you think their margins are with their current pricing for it
If the best way to predict is to control, does that bode well for AI alignment?

@badlogicgames wake up babe a new Mario recommended viewing just dropped
I take advantage of the fact that many LLMs know nothing about me to ensure I get unbiased answers. For people pushing memory and integrations super hard, how do you handle bias?
As compute gets scarcer, I wonder how far closed source labs will go down the hardware quality stack, primarily weighing revenue vs risk of weight exfiltration. If the risk of weight exfiltration is large enough, then the market size for mid to low tier hardware not connected in large racks or with access to deals with large labs decreases dramatically imo.



The Innovasion Game C... @TIGfoundations
3 Followers 474 Following The Network for Algorithmic Breakthroughs https://t.co/T1xSPFJVpb
Ogunflow @Paul26ix
1K Followers 1K Following i put $20m in a DEX on a budget under $100k // ex growth lead, head of bd // clarity breeds scale 🧊
Robert Scoble @Scobleizer
586K Followers 50K Following San Francisco/Silicon Valley AI | Robots, holodecks, BCIs, analysis of new things | Ex-Microsoft, Rackspace, Fast Company | Wrote eight books about the future.
Dolphin @dphnAI
6K Followers 1K Following AI Lab developing uncensored models & distributed inference ⟠ Over 5m monthly downloads on Hugging Face ⟠

David Crawshaw @davidcrawshaw
12K Followers 1K Following ceo https://t.co/rCiZyr11L3, co-founder and ex-cto @Tailscale. forever a programmer

NeuronBizdev @NeuronBizdev
1K Followers 776 Following passionate about art of communication SDR lead @sherlockdefi prev. head of eco @empe_io, lead BD @coinstructweb3, host @SafeYieldClub, lead BD @TYMIOapp
finne @0xfinne
2K Followers 4K Following shit coin trader uniswap v4新hook监控+ai评分频道: https://t.co/9ydeK813MR
Richard Berry @_richardberry
17 Followers 133 Following Helping to build entrepreneurial ecosystems @Uni_Newcastle
iam @yourenotiam
178 Followers 1K Following software dev, will work for free if it’s interesting, or truth related.

Michal Majzlík @michalmajzlik
176 Followers 215 Following Technology is taking over our lives an I am excited to be part of it.


Kyle Ryan @kyjry
124 Followers 814 Following Head of R&D @ Pensar && Adjunct Professor of Computer Science @ Fordham University

François Altwies @francois352
2K Followers 8K Following Human Potential Developer Neurofeedback Trainer @ https://t.co/f4a63Hkg4k https://t.co/AfdIySK2dd
InternationalOptions @IntlOptions
110 Followers 1K Following Rare signals carve out distinct subspaces in the latent space without dilution

Ken Thompson @Ken808Thompson
263 Followers 2K Following I'm much better at doing things than saying things, so enjoy my social awkwardness immortalized.
Paul Itoi @paulitoi
1K Followers 1K Following
Nadeem @8W7O7
37 Followers 414 Following Specifically here for the applied LLM research and design community. Ex-@Meta @Uber @Wayfair
Mbaunguraije Tjikuzu ... @mtjikuzu
827 Followers 5K Following Research | ICT Projects | Cyber Security
Aditya @adrian2in
8 Followers 5K Following
Vamsi Bedapudi @wamsib
209 Followers 2K Following Stumbling through life, one step at a time MTS @ResolveAI Ex-Gemini @GoogleDeepMind CS @iitbombay Views are my own.

Cristiano Messi @messi12156
32 Followers 3K Following
Jianguang Zuo @jianguang_ZUO
87 Followers 6K Following
hari_haran @HariAyapps
626 Followers 1K Following Building @archgen_ | @TXInstruments | @lossfunk | NITK'23


DG @dgmonsoon
796 Followers 1K Following cofounder @midcenturyai prev @stanford @ycombinator @salesforce @replit
Al-ameen @alameenpd
920 Followers 1K Following founder @retaindb @badtheorylabs. . swe + ai/ml engineer . cracked asf

Daniel Lougen @DJLougen
2K Followers 543 Following PhD @ UofT | Visual Neuroscience | Gestalt Labs | Qwen Dev Ambassador
kaios @kaiostephens
25K Followers 398 Following larping | working on @nipuxx | data science @uwaterloo
Jane Basten @basten_jane
2K Followers 4K Following
SrMessi.s◎l 🇦�... @0xSrMessi
12K Followers 7K Following @MetaDAOProject & @futarddotio intern. @Ownershipfm Growth Lead. @P2Pdotme 🇦🇷 KM & 🇲🇽 CA. Managing the biggests loans of the country 🏦.


Ian @fewgoodcoins
76 Followers 372 Following

Dean | Realms @deanmachine
20K Followers 4K Following Building @ridemarkets - conviction markets on solana, futarchy for treasury Director @realmsDAOs Sowellian Governance Maxi

Ralph Pearson @Ralph_Pearson_
1K Followers 1K Following Chief Financial Officer at @Magnus_Fund | DeFi supporter For business: [email protected]

Lawyered @BitGrateful
20K Followers 7K Following business lawyer for 15 years. advising founders on crypto and AI deals & compliance.
Chi Jin @chijinML
8K Followers 521 Following Researcher @OpenAI | Associate Prof @Princeton AI Reasoning · Reinforcement Learning · Game Theory · ML Foundations
Sergey Levine @svlevine
129K Followers 143 Following Associate Professor at UC Berkeley Co-founder, Physical Intelligence
Noah Ziems @NoahZiems
4K Followers 2K Following Applied Research @PrimeIntellect. Prev @MIT_CSAIL under @lateinteraction, PhD @NotreDame
mass @Memetic_Theory
7K Followers 3K Following building the first autonomously self improving company. coo AlphaFund
Richard Sutton @RichardSSutton
64K Followers 59 Following Student of mind and nature, libertarian, chess player, cancer survivor. @ Keen, UAlberta, Amii, https://t.co/u8za2Kod54, The Royal Society, Turing Award
Chris Painter @ChrisPainterYup
6K Followers 1K Following president @METR_Evals, evals accelerationist, working hard on AGI preparedness


Mark Saroufim @marksaroufim
16K Followers 983 Following Amdahl comes for us all mts & co-founder @coreautoai @pytorch @gpu_mode enjoyer
Seth Karten @sethkarten
2K Followers 670 Following Agents….Continual Harness, PokeAgent, LLM Economist | Research Intern @PrimeIntellect | CS PhD @Princeton | Former CMU Waymo
Cassi @Cassi_on_X
82 Followers 6 Following
Sakana AI @SakanaAILabs
73K Followers 0 Following Sakana AI is an AI R&D company based in Tokyo. Try Sakana Chat → https://t.co/1m2lSgnfB2
Skyler Miao @SkylerMiao7
16K Followers 307 Following Head of Engineering @MiniMax_AI Building MiniMax M3.x, Code, Audio and @Hailuo_AI
elie @eliebakouch
17K Followers 4K Following training llm @PrimeIntellect (prev: @huggingface) anon feedback: https://t.co/JmMh7Sg3mL
Parallel Web Systems @p0
19K Followers 42 Following Infrastructure for intelligence on the web. Start here → https://t.co/0Enegj3L73
Arjun Balaji @arjunblj
74K Followers 4K Following investing/research @paradigm, technology, history, strategy games, boston sports. optimist
Chelsea Finn @chelseabfinn
95K Followers 399 Following Asst Prof of CS & EE @Stanford Co-founder of Physical Intelligence @physical_int PhD from @Berkeley_EECS, EECS BS from @MIT
Danijar Hafner @danijarh
30K Followers 1K Following Building AI that autonomously understands and interacts with the world. Previous: @GoogleDeepMind @UCBerkeley @UofT
The Innovation Game (... @tigfoundation
10K Followers 5 Following The Network for Algorithmic Breakthroughs https://t.co/APlJSBonZF
Durk Kingma @dpkingma
55K Followers 403 Following @AnthropicAI. Prev. @Google Brain/DeepMind, founding team @OpenAI. Computer scientist; inventor of the VAE, Adam optimizer, and other methods. ML PhD.
rohit @krishnanrohit
32K Followers 2K Following Essays: https://t.co/TbCaC6VaaM | Book: https://t.co/aykZirs43Y | Senior Fellow @wharton | World model: (incoming)
Abhijay Rana @abhijaymrana
914 Followers 415 Following scaling reward models & brokering data | briefly @ucberkeley

Lightning Rod Labs @lightningrodai
183 Followers 49 Following Turn real data into labeled datasets, instantly⚡️
Cortical Labs @CorticalLabs
14K Followers 7 Following What happens when you grow an organic mind in a digital world?
Tim Rocktäschel @_rockt
46K Followers 2K Following Co-Founder @Recursive_SI, Professor of AI @AI_UCL, PI @UCL_DARK, Fellow @ELLISforEurope. Ex @GoogleDeepMind @AIatMeta @CompSciOxford
Teortaxes▶️ (Deep... @teortaxesTex
64K Followers 3K Following We're in a race. It's not USA vs China but humans and AGIs vs ape power centralization. @deepseek_ai stan #1, 2023–Deep Time «C’est la guerre.» ®1
Prophet Arena @ProphetArena
2K Followers 19 Following The AI benchmark for predictive intelligence | SIGMA Lab @UChicagoCS @DSI_UChicago Not affiliated to any tokens or crypto protocols.
Ning Ding @stingning
7K Followers 400 Following Researcher of AI. Assistant Professor @Tsinghua_Uni. Working on scalable methods of language and physical models @nature_will_ai.
Jan Leike @janleike
132K Followers 335 Following AI research @AnthropicAI. Previously OpenAI & DeepMind. Optimizing for a post-AGI future where humanity flourishes. Opinions aren't my employer's.
Noam Brown @polynoamial
128K Followers 910 Following Researching reasoning @OpenAI | Co-created Libratus/Pluribus superhuman poker AIs, CICERO Diplomacy AI, and OpenAI o-series 🍓 reasoning models
Forecasting Research ... @Research_FRI
4K Followers 26 Following We advance the science of forecasting to improve decision-making on high stakes issues. Co-founded by chief scientist Philip Tetlock.
Alham Fikri Aji @AlhamFikri
5K Followers 429 Following Faculty at @MBZUAI, @MonashIndonesia | Visiting research scientist @Google | Washed competitive programmer. IOI medalist
Dylan Patel @dylan522p
135K Followers 1K Following SemiAnalysis Boutique AI Infrastructure Research and Consulting DMs are open for consulting, quotes, or to talk shop, Opinions my own

kalomaze @kalomaze
24K Followers 3K Following ML researcher (@primeintellect), speculator • extremely silly jester
Softmax @softmaxresearch
1K Followers 32 Following Softmax's mission is to scale organic alignment. We approach this problem with multi-agent reinforcement learning population-based simulations.
Dolphin @dphnAI
6K Followers 1K Following AI Lab developing uncensored models & distributed inference ⟠ Over 5m monthly downloads on Hugging Face ⟠

leo 🐾 @synthwavedd
13K Followers 3K Following tech, ai & politics nerd || got info you think i'd be interested in? let's talk! [email protected]
Internet Backyard @netbackyard
832 Followers 65 Following The Financial Operations Platform for Compute
mai @omaikasei
2K Followers 346 Following plotting @netbackyard | instigated @buildredthread dillied dallied @TheSanctuaryAI

Subquadratic @subquadratic
20K Followers 938 Following AI lab leading the subquadratic LLM revolution.
Jack Clark @jackclarkSF
133K Followers 5K Following @AnthropicAI, ONEAI OECD, co-chair @indexingai, writer @ https://t.co/3vmtHYkIJ2 Past: @openai, @business @theregister. Neural nets, distributed systems, weird futures
Jack Lindsey @Jack_W_Lindsey
18K Followers 251 Following Neuroscience of AI brains @AnthropicAI. Previously neuroscience of real brains @cu_neurotheory.

Anjney Midha @AnjneyMidha
47K Followers 3K Following founder @amppublic • visiting scientist @stanford • teaching @cs153systems
Rahil Mittal @mittal_rahil
582 Followers 647 Following The greatest twatterer in the history of ever. @uofillinois
Ryan Greenblatt @RyanPGreenblatt
9K Followers 6 Following Chief scientist at Redwood Research (@redwood_ai), focused on technical AI safety research to reduce risks from rogue AIsTrends for United States
You might like



















